1 Version Control Systems
1.1 The importance of making research code accessible
In research, the dissemination of results is a common practice, but there exists a critical gap. While publishing data when publishing a research manuscript is getting more established, publishing the code used to get these results is not. A striking revelation from 2016 Nature survey conducted by Monya Baker Baker (2016) of 1,576 researchers underscores the issue: more than 70% of researchers struggled to reproduce another scientist’s experiments, and a staggering 50% encountered difficulties in reproducing their own experiments. This alarming trend sheds light on a pressing crisis in research reproducibility, jeopardizing the credibility of scientific findings.
The heart of the matter lies in the omission of research scripts and code - the very essence of the analytical processes shaping research outcomes. While research papers document results, the absence of the scripts used to generate these findings poses a significant barrier to the reproducibility of experiments. In an era where openness and collaboration are championed, this discrepancy in sharing the tools that drive research threatens the very foundation of scientific enquiry.
1.2 Introduction to Version Control Systems
Chances are that you have encountered been using a form of version control system before without realising. Consider the scenario below in Figure 1.1, where a PhD student sends their final manuscript draft to their supervisor. The supervisor sends back the document with comments and feedback to the student, renaming the document with a new version name. Before you know it, this iterative exchange has resulted into 22 versions of the file. Renaming and tracking the progression of the manuscript exemplifies a basic version control method.

A version control system, in essence, is a tool that keeps track of the changes and versions of a file. This facilitates collaboration amongst multiple individuals working on the same project concurrently. Version control systems allows users to compare changes between different versions of the file, revert changes, and track who, when and why modifications were made within the team.
Version control systems are popular in the software development industry as it allows teams to have a common location or repository where all the source code/files in the project are kept and thus allowing team members to work on the same project concurrently in a collaborative way, tracking their contributions to the project. However, increasingly, researchers from different domains are using version control systems, in an effort to make their analysis transparent and accessible enabling reproducibility of their work.
The main advantages of version control systems are:
Versioning: Every time someone makes a change to a file, a version of that file is stored by the version control system. This removes the need to rename the files manually to keep track of the different versions.
Collaboration: Version control systems allow more than one person to work on the same file at the same time. This collaborative feature fosters efficient teamwork, as contributors seamlessly integrate their modifications into a shared project.
Backup: While not being their primary role, version control systems safeguards against data loss. By storing code on a server or in the cloud, these systems serve as an inadvertent backup solution, mitigating the risk of losing all work in the event of a computer breakdown.
In version control systems, a repository is a data structure that stores files and directory structure in it, as well as the history of changes made to those files. This is similar to folders on your computer.
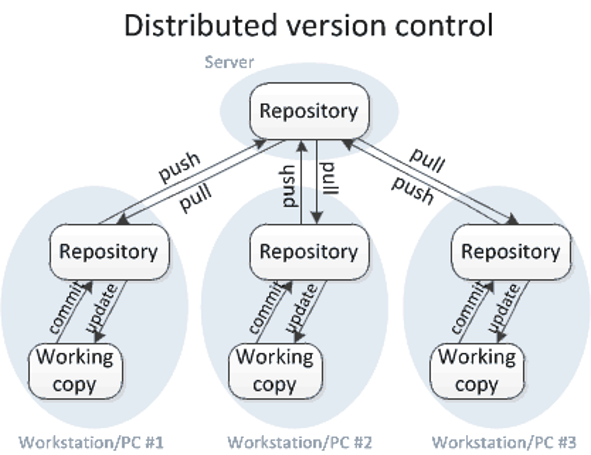
Version control systems are often categorised as either centralised version control systems or distributed version control systems.
1.2.1 Centralised Version Control Systems
In a centralised version control system, the project files are stored in a central place (server) which also keeps track of the files’ history (versions). This setup allows people to collaborate on the same project with users able to commit or make changes to a central server. Normally multiple users are not able to work on the same file concurrently in a centralised version control system. The user working on a file would normally “lock” a file for editing, restricting editing access to other users. Examples of centralised version control systems are CVS and Subversion (SVN). Them main disadvantage of these systems are that if the server goes down, none of the users will be able to collaborate or get the latest versions of the files from the repository.
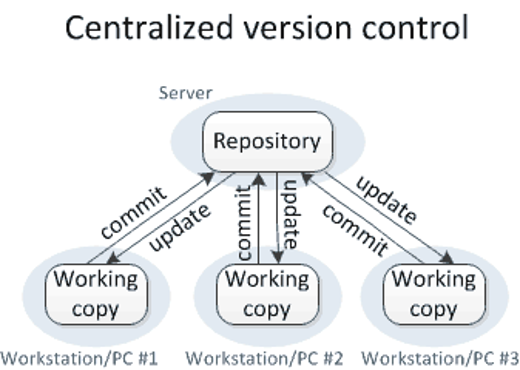
1.2.2 Distributed Version Control Systems
In a distributed version control system each person in a team working on a project makes a copy or clones the repository on their own computer which also includes the full history of the different files inside the repository. Thus if a server goes down, it would be able to be restored back from the copies of the repositories held by the different people in the team. Distributed version control systems are becoming increasingly more popular as they overcome some of the limitations imposed by centralised version control systems. In this course we will be learning about git which is an example of a distributed version control system.